Monitoring: Mehr als Ping
Das Monitoring im Unternehmensnetzwerk ist ein vielfach unterschätztes Hilfsmittel, wenn es um die Produktivität geht. Schnelle Verständigung und verbesserte Fehleranalyse machen es unverzichtbar.
Übersicht im Blick
Die Vielfalt und deren Abhängigkeiten in einem Unternehmensnetzwerk ist ein großes Problem für die interne IT. Die ständige Überwachung aller Systeme auf Ausfälle oder andere, noch schwieriger zu erkennende Probleme, ist mit Manpower nicht zu leisten. IT-Admins haben genug zu tun.
Hier hilft die Automatisierung dieser Überwachung. Ein System, welches uns jederzeit einen Live-Einblick in den Zustand aller Server und Dienste bietet.
Mehr als Hardware
Dabei geht es um viel mehr als nur den Ausfall von Hardware. Die Funktionalität der einzelnen Dienste im Unternehmensnetzwerk muss gewährleistet sein. Ob der Mailserver funktioniert, wird nicht durch eine Uptime des Exchange-Servers beurteilt.
Der SQL-Server gilt nur als „UP“, wenn die Datenbank sauber und performant die Antworten liefert.
Zu den einzelnen Serveranwendungen kommen aber noch eine Vielzahl von Diensten, die für einen reibungslosen Betrieb unverzichtbar sind. Wenn der DNS-Server ausfällt, haben Sie ein großes Problem. Wenn das Active-Directory nicht sauber synchronisiert, merken Sie es vielleicht viel zu spät. Und Ihre gesamte Infrastruktur fährt gegen die Wand fährt.
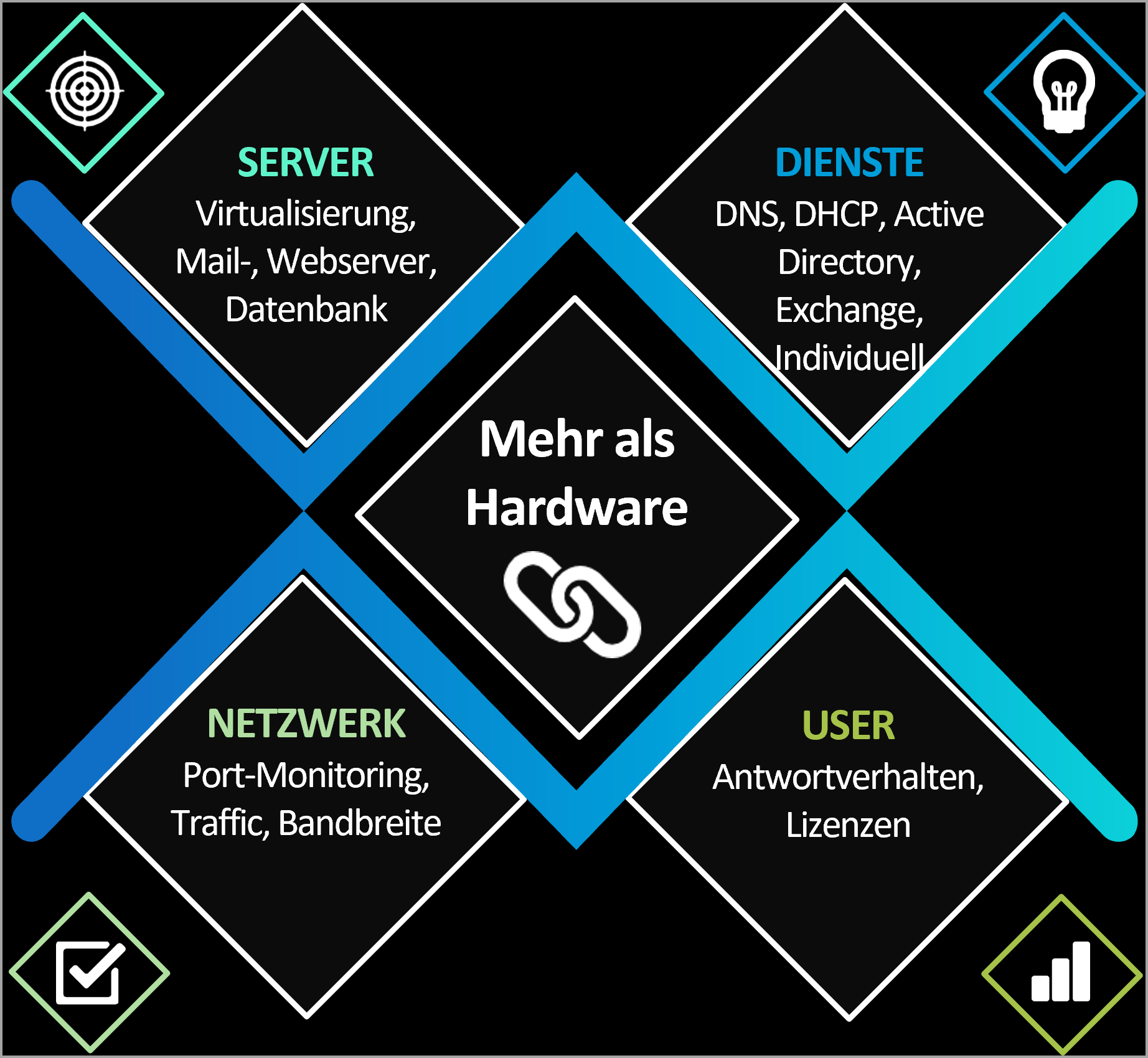
Aber auch „kleine“ Störungen können große Auswirkungen haben. Stellen Sie sich nur vor, wenn der DHCP-Server keine IP-Adressen mehr liefern kann.
Dazu kommt noch die gesamte Netzwerk-Infrastruktur. Router, Switche und Firewalls müssen nicht nur laufen, sondern auch den benötigten Traffic liefern können. Der Klassiker: die Internet-Bandbreite. Wissen Sie zu jeder Zeit, ob es hier – und sei es auch nur temporär – Engpässe gibt? Reicht der Durchsatz im Switch-Uplink? Wie sieht es mit den VPN aus?
Nicht zuletzt spielt das Antwortverhalten eine entscheidende Rolle. Wenn Anwender über langsame Systeme klagen und ihre Arbeit nur mühsam erledigen können, hat Ihr Monitoring bereits rechtzeitig angeschlagen. IT-Admins reagieren noch bevor es zu Einschränkungen im Betrieb kommt.
Ausfall mit Ankündigung
Jede Überlastung eines Systems erfolgt meist in Phasen.
Tritt ein ungewöhnlicher Zustand auf, wird der Admin bereits informiert. Ohne Monitoring merkt der User nach einiger Zeit die Verlangsamung des Systems und darauf folgt der Stillstand. Hier wird wertvolle Zeit verschwendet, den sich ankündigenden Fehler rechtzeitig zu beheben.
Alarmierung auf unterschiedliche Art
Der Alarm selbst wird auf unterschiedlichste Weise an den verantwortlichen Admin gemeldet. Für harmlosere Störungen oder solche, die mit reichlich Vorlauf erkannt werden, reicht meist eine E-Mail an das Support-Postfach. Denken Sie an das allmähliche Voll-Laufen des Laufwerks am Fileserver. Hier kann rechtzeitig reagiert werden, noch bevor es nur in die Nähe einer Störung kommt.
Der Ausfall einer Festplatte kann schnell kritisch werden – auch wenn hier ein RAID im Einsatz ist. Hier gilt es rasch zu reagieren und den Austausch einzuleiten. Ein automatisch generierter Eintrag im Ticket-System könnte hier die passende Variante sein.
Stillstand eines Systems darf nicht von E-Mail abhängig sein. Neben der guten, alten SMS sollte hier eine sofortige Push-Mitteilung die Verantwortlichen informieren. Eine gute Kommunikation an die Anwender trägt auch hier zur besseren Akzeptanz bei.
Und das Gute daran: die Administratoren können im Alltag ganz entspannt sein. „Keine Nachricht ist eine gute Nachricht!“ lautet die Devise. „Gibt es ein Problem mit dem Mailserver?“ kann schnell und einfach beantwortet werden. Dank unserem Monitoring.
Aber auch die Eskalationskette bei einem Ausfall erledigt das Monitoring. Nach 5 Minuten vom Techniker noch immer keine Reaktion? Die nächste Meldung geht an den nächsten Ansprechpartner in der IT.
Vielfältige Einsatzgebiete
Sehen wir uns kurz die Einsatzgebiete etwas detaillierter an. Da gibt es zum einen die Klassiker: Ausfälle einer Hardware-Komponente oder auch nur deren Ankündigung. Das Voll-Laufen einer Festplatte. Die vollständige Auslastung einer CPU über mehrere Minuten.
Hier kann von der IT schnell reagiert werden. Meist bekommt der Anwender davon gar nichts mit.
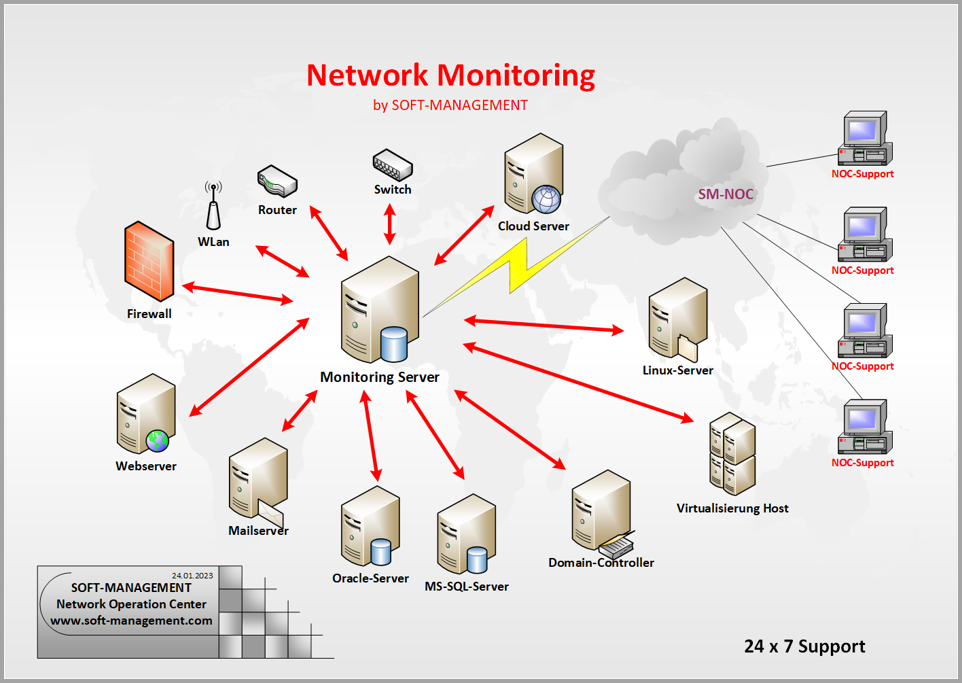
Der Ausfall eines Dienstes muss nicht gleich zum Stillstand führen. In vielen Fällen ist dies ein schleichender Prozess. Klassisch hier der Sync der Domain-Controller. Ohne Monitoring fällt der Fehler vielleicht erst Wochen nach dem Eintritt auf. Nämlich dann, wenn Änderungen vorgenommen wurden und diese auf beiden DCs völlig unterschiedlich abgebildet werden. Dann ist Hektik angesagt. Unnötig, wenn der Fehler sofort nach Eintritt vom Monitoring gemeldet wurde.
Aber auch die Antwortzeiten von Datenbank- oder Webservern sind ein gutes Indiz für auftretende Probleme. Meist mit viel Vorlauf vor dem vom Anwender bemerkten Ausfall.
Die Überwachung von Eventlogs darf hier natürlich auch nicht fehlen. Kein Grund tausende Einträge zu prüfen. Ein gut konfiguriertes Monitoring filtert aus der Masse die kritischen Meldungen.
Schlechte Performance ohne Ausfall
Ohne ein performantes Netzwerk funktioniert der beste Server nicht. Hier gilt es alle kritischen Ports im Blick zu haben. Die Aufzeichnung fehlerhafter Pakete erleichtert die Analyse. Die Überlastung einzelner Schnittstellen – sei es auch nur zu bestimmten Zeiten – gibt schnell Aufschluss, dass nicht der Server das Problem ist.
Und natürlich fehlt auch der Klassiker nicht: Die Auslastung der Internet-Bandbreite. Im Zeitalter der Cloud-Nutzung ein sehr wichtiger Parameter für einen störungsfreien Betrieb. Das Monitoring liefert hier nicht nur Ad-Hoc-Werte, sondern auch wertvolle Trend-Analysen.
Individualisierung
Die Möglichkeiten des Monitorings sind vielfältig und individuell. Von der Laufzeit einer USV im Fall eines Stromausfalls – vielleicht sogar in Kombination mit einem automatisierten Shutdown der Server – über die Temperatur-Messung im Serverraum, bis hin zur Überwachung des Patch-Stands der Windows-Hosts.
Oder einen Blick auf den Stromverbrauch der Systeme?
Ein Monitoring-System ist aber kein Out-of-the-Box-Produkt. Es muss auf die individuellen Anforderungen angepasst werden.
Baselining
Das Baselining ist die erste und wichtigste Anpassung. Hier wird festgelegt, was in Ihrem Unternehmen als „normal“ einzustufen ist.
Einfaches Beispiel: Eine CPU-Auslastung von ständig 50 Prozent kann auf einem Datenbank-Server normal sein. Für einen Domain-Controller ist dies sicherlich ungewöhnlich.
Gleiches für die Internet-Bandbreite. Eine Volllast, wenn das Backup in die Cloud kopiert wird, ist normal. 100 Prozent über mehrere Minuten tagsüber wahrscheinlich nicht.
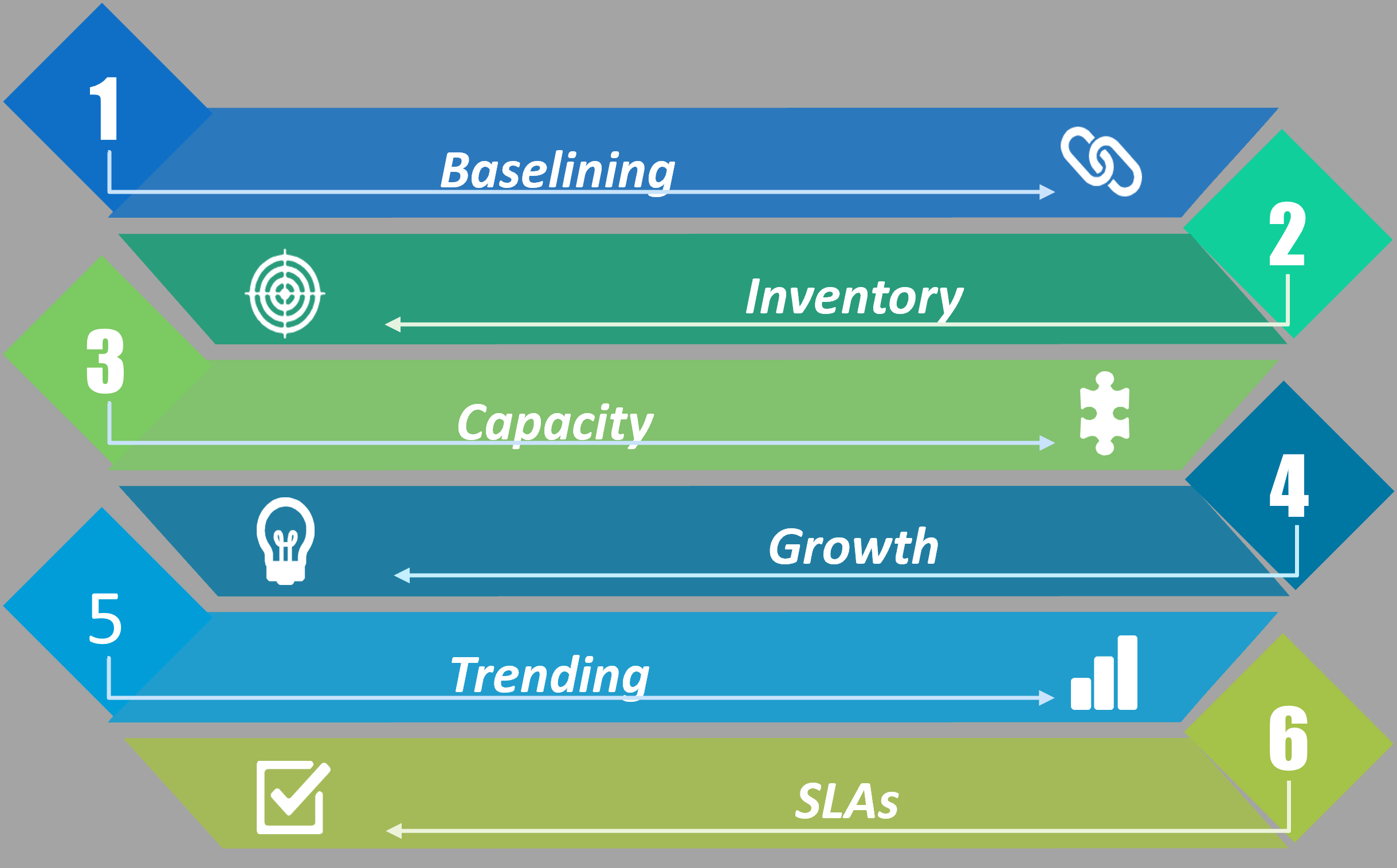
Bestandserfassung
Zweiter Punkt: Die Bestandserfassung. Hier geht es nicht nur um einen Überblick über die IT-Infrastruktur, sondern bis ins Detail für jeden Dienst. Ein wichtiger Windows-Service für eine Drittanwendung gehört genauso in das Monitoring wie die Hardware. Auch die Abhängigkeiten sind hier zu berücksichtigen. Der Fehler in einem Dienst kann einen Ausfall an ganz anderer Stelle als Ursache haben.
Wachstum und Kapazität
Kapazität und Wachstum sind entscheidende Punkte, wenn es um das Thema Investitionen geht. Das Monitoring bringt beides, schön dargestellt in grafischer Form, in Langzeitinformationen als Entscheidungsgrundlage. Der Klassiker ist hier das Wachstum im Storage-Bereich. Wie viele Reserven sind vorhanden? Und wie nimmt die Auslastung in den letzten Monaten oder Wochen zu?
Hier geht es einerseits um die rechtzeitige Reaktion auf das Wachstum, aber auch um die richtige Einschätzung der Anforderungen in der Zukunft. Fakten statt Schätzungen. Die Trend-Grafik ersetzt das Bauchgefühl.
Und nicht zuletzt der heikle Punkt der Reaktionsgeschwindigkeit. SLA ist hier das Stichwort. Hier gibt es vielleicht Verträge oder auch „nur“ den Anspruch durch die Unternehmensleitung.
Alles ok?
Wenn Sie ein Monitoring einsetzen, werden Sie sofort DEN großen Vorteil zu schätzen wissen: den Überblick über den Gesamtzustand. Größere Umgebungen setzen hier auf ein fest installiertes Display im IT-Bereich. Dieses zeigt auf einfache und dennoch voll-umfassende Weise den Status aller Komponenten. Gelb als Vorwarnung und rot, wenn es sofortigen Handlungsbedarf gibt. Für alle IT-Mitarbeiter jederzeit sichtbar.
Einmal getestet, immer geliebt
Vielfalt der eingesetzten Systeme und Dienste besser in den Griff zu bekommen.
Proaktives Handeln statt Reaktion auf User-Meldungen bringt den IT-Support auf ein neues Level.
Auch die Kommunikation im IT-Team wird dadurch verbessert. Ein Kommentar des IT-Mitarbeiters im Ticket zu einer Störungsmeldung und alle im IT-Team wissen Bescheid. Keine unnötigen E-Mails. Und auch die Anwender profitieren von der effizienter gestaltenden Diagnose.
Wie eingangs gesagt: wenn Sie einmal das IT-Management um ein Monitoring-System erweitert haben, werden Sie es nicht mehr missen wollen. Schnellere Reaktion, entspannteres Arbeiten – auch im Störfall – und bessere Diagnosen werden den IT-Support auf ein neues Level heben.
Testen Sie es. Sie werden es nicht bereuen.
Das Video zum Thema
Vielleicht überzeugen Sie – oder Ihren Chef – bewegte Bilder mehr als Text. Aus diesem Grund gibt es die Ausführungen auch in Videoform auf unserem YouTube-Kanal.